
Rethinking Modern Asynchronous Paradigms
Most developers deal with some sort of asynchronous operation day to day. For most of us, it is I/O (Input & Output). A web developer does network calls, a systems developer could do some file operations, both are based on a submit and wait system, where program waits until some operation is completed. Different programming languages provide different ways to write code that is asynchronous, as developer wants to utilize the processor during the "wait" phase, by either doing more operations or yielding some CPU cycles back to the host until the async operation finishes, so other processes continue running.
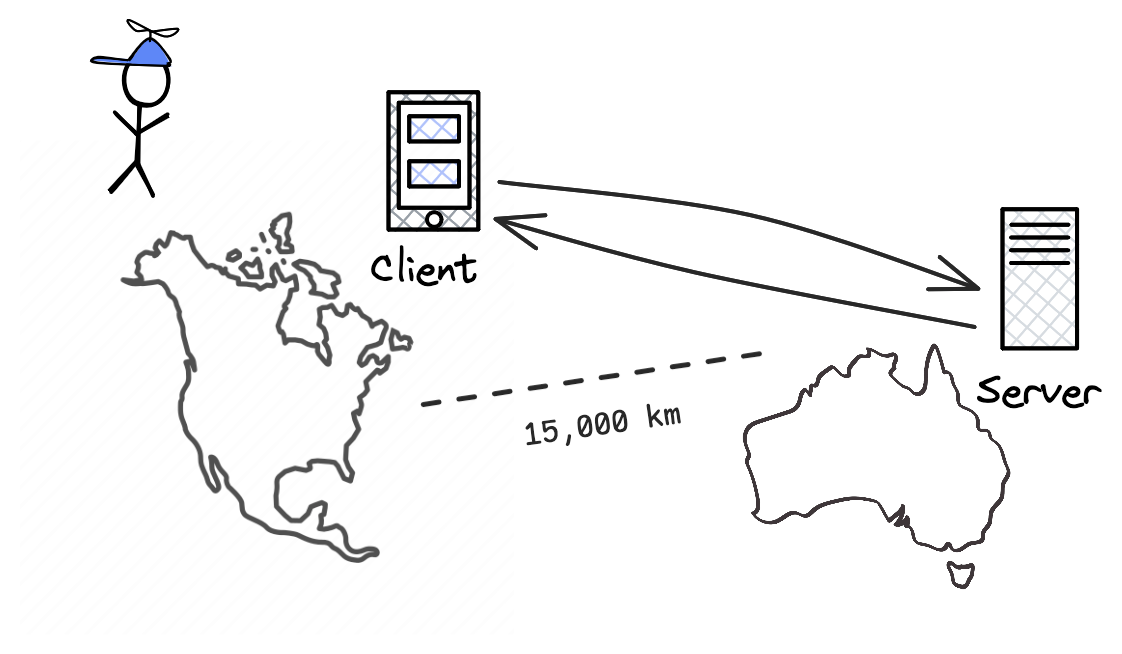
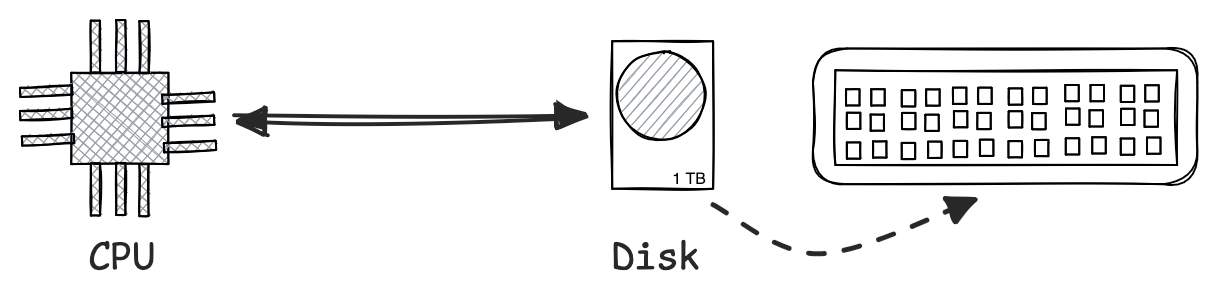
For reference, if you have a 4 GHz CPU and the fastest NVMe SSDs, it takes about 0.01 milliseconds of latency to read something from the disk. This is about 40,000 CPU cycles wait, just to read something from the disk that is on your computer. Moreover, if you live in New York city and the servers are located in Chicago, it takes around 20 milliseconds just to do a roundtrip without any additional operations, which takes about 80,000,000 spare cycles.
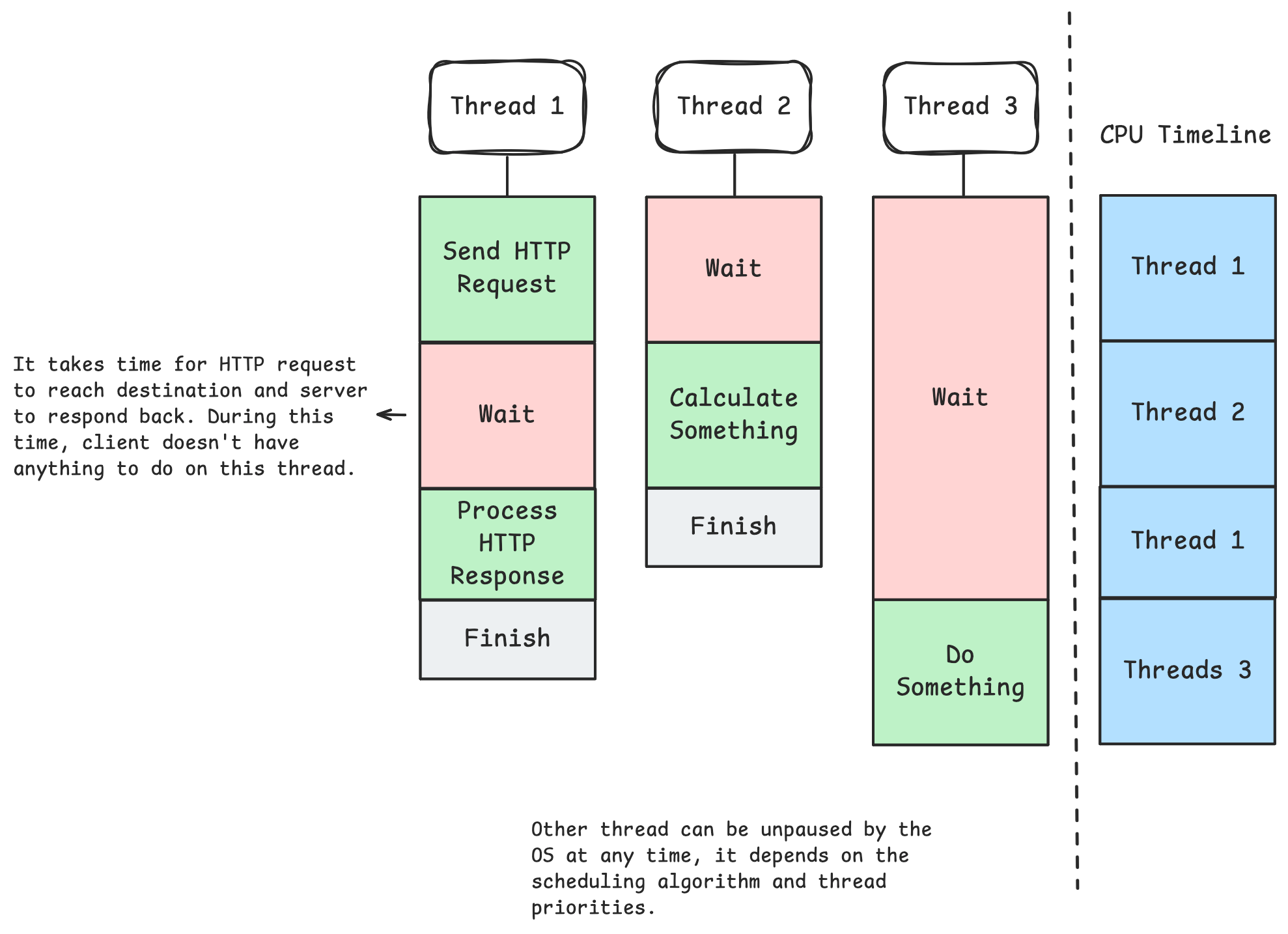
If your code is running in an operating system, normally the code you write runs sequentially inside the main thread within a process. The OS handles concurrent operations by switching threads super-fast. If your CPU has only 1 core, it can only run 1 thread simultanously. However, from a users perspective, this doesn't sound right, as you can run multiple programs at the same on your OS, while using your keyboard and mouse. This magical effect is achieved by pausing and unpausing threads super quickly, so the user can't feel there had been micro pauses.
From an application developer's perspective, how do you know your code is waiting for something to finish? Let's start with an explicit wait, Thread.sleep(milliseconds). Assume you are sending some notification, but you don't want to annoy the user by sending them notifications too quickly. So let's wait 2 seconds after each notification is sent. Assume sending a notification is real time for now.
sendNotifications(notifications: List<Notification>) {
for (Notification notification : notifications) {
notification.send();
Thread.sleep(2000);
}
}When you call Thread.sleep(2000), your program notifies the OS that current thread doesn't want to run for the next 2000 milliseconds. Therefore, the thread is blocked for the next 2 seconds, as it doesn't run any other code. OS will take that thread, suspend it until that given time is passed and it will run other important stuff that needs to be done in the meanwhile, such as rendering stuff on screen or processing background messages.
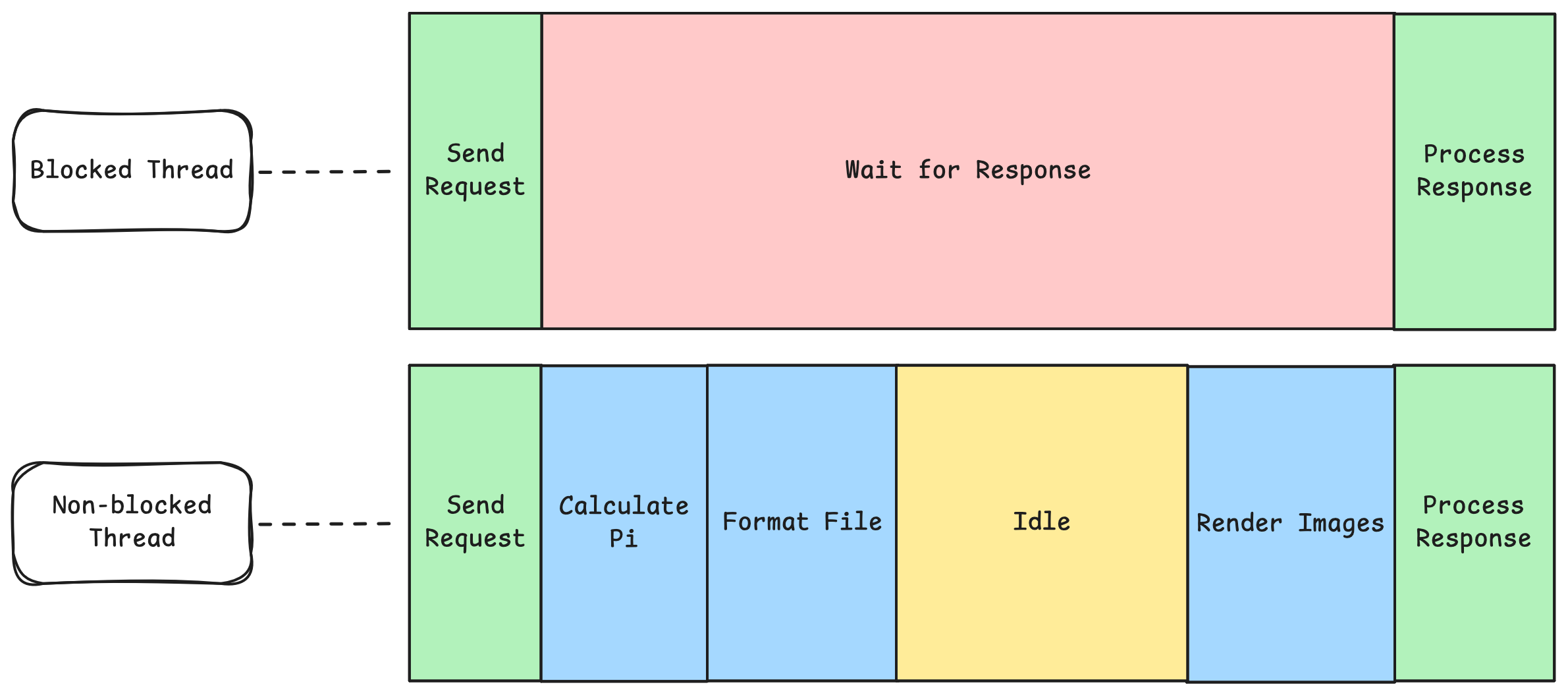
Instead if you wrote some dumb code like
long now = System.currentMillis();
while (System.currentMillis() <= now + 2000) {}You will keep wasting CPU cycles, even though you are not doing any valuable calculation. Even though OS will probably pause your thread and do other stuff in the background, it might struggle with scheduling it efficiently, so background tasks might run slower, you might feel like your computer is less responsive and of course, as you are not leaving any spare CPU cycles.
In this scenario, we look at only one thread, but in most applications, we spawn more thread called "background threads" to run stuff concurrently inside our application.
Let's say you receive some messages from an outside source. You have a web application and you are constantly receiving messages from users and you need to send notifications to the respective target. In this case, you need a background thread that helps you receive those messages. And when you receive a message, you can send those notifications in a separate thread, so you don't block any other notification from being received and processed.
Thread worker = new Thread(() -> {
while (!Thread.currentThread.isInterrupted()) {
List<Message> messages = pollMessages();
messages.forEach((message) -> {
Thread sender = new Thread(() -> {
sendNotifications(message.notifications);
});
// Start sending but don't wait until it finishes
sender.start();
});
// Rate limit poll messages to prevent self DDoS
Thread.sleep(1000);
}
});
// Start the thread
worker.start();
// Wait until Thread exits (until OS interrupts)
worker.join();First glance, this looks fine, we are creating a separate thread for each send operation, so the operating system handles concurrency for us. However, creating a threads is not cheap, it allocates lots of OS-level resources, so it is a relatively slow operation.
So another idea is to use Thread Pools, where we initialize the threads beforehand, so we can omit the expensive resource and time cost of initializing threads.
ExecutorService notificationPool = Executors.newFixedThreadPool(10);
Thread worker = new Thread(() -> {
System.out.println("Background listener thread started.");
while (!Thread.currentThread().isInterrupted()) {
List<Message> messages = pollMessages();
messages.forEach((message) -> {
notificationPool.submit(() -> sendNotifications(message.notifications));
});
// Rate limit poll messages to prevent self DDoS
Thread.sleep(1000);
}
});
// Start the thread
worker.start();
// Wait until Thread exits (until OS interrupts)
worker.join();
// Shutdown thread pool after use
notificationPool.shutdown();
notificationPool.awaitTermination(30, TimeUnit.SECONDS);Here, we have set a size for the thread pool. This thread pool size is basically our maximum concurrency limit. We can't send notifications concurrently to more than 10 users with this setup. So let's think how we can handle this.
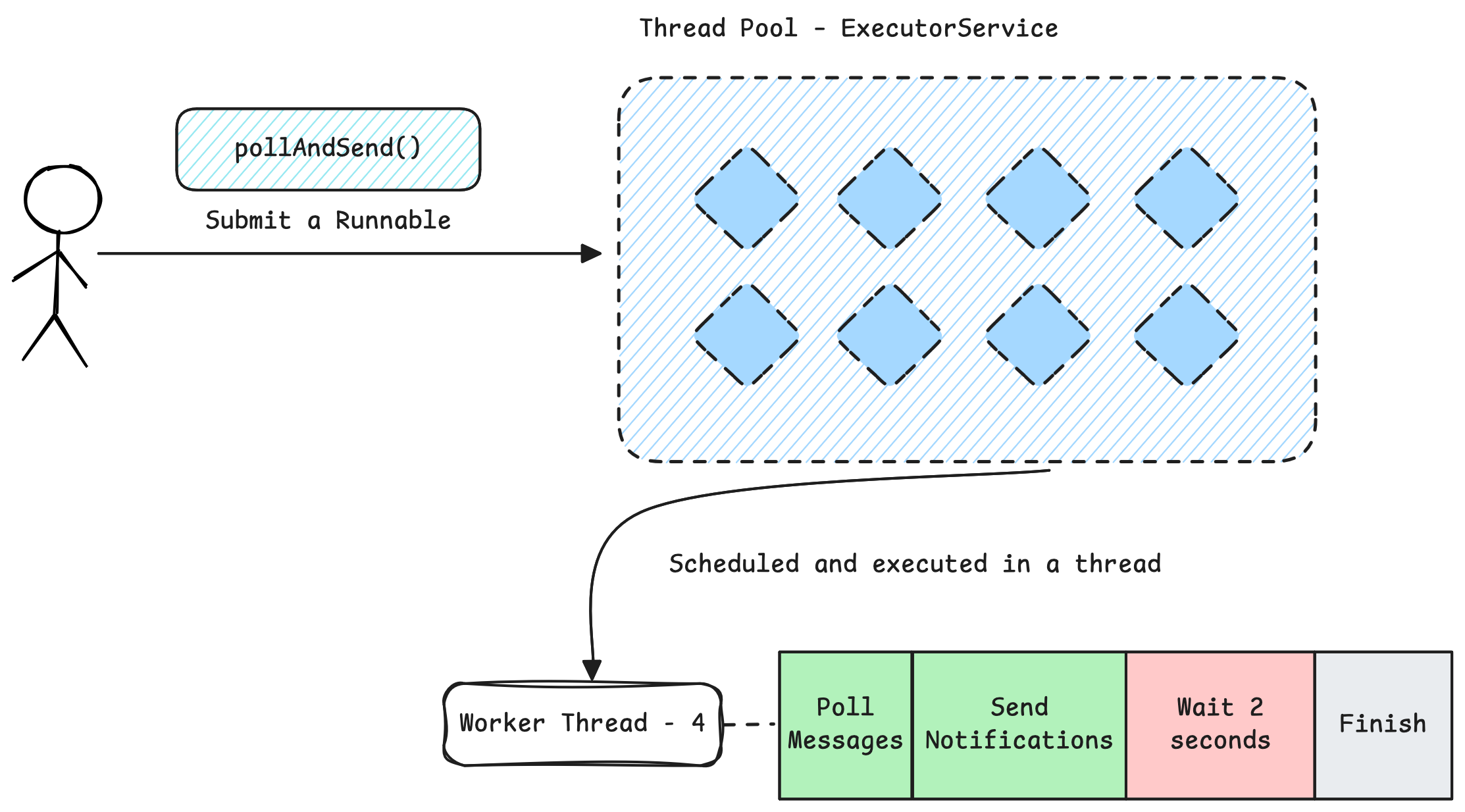
The core issue with 10 user concurrency is the amount of time it takes when you call send notifications. If sending notifications took only a couple CPU cycles, running 10 threads would be more than enough! But our assumption of sending notification taking couple CPU cycles is wrong, in reality, those send notification calls are usually happening over network and takes a long time as we discussed. During those network calls, our threads would be blocked.
Note: If you want to run it with minimal overhead, you could choose number of threads to be equal to 2 times number of CPU cores. Usually modern CPUs have 2 logical cores on a single physical core, thus they can run two threads real time per core.
So how can we make the send notification only run instructions that are wait-free? It is important that we move everything related to wait outside this thread pool. Why? Because anything that does a wait, basically occupies and blocks your Thread from executing other code, even though it is technically doing nothing. So, here comes the idea of Event Loops. Where we run code that is doing only non-blocking operations, which means thread is newer blocked on a wait operation, or something super CPU intensive, such as a crypthographical calculation. On this loop, we will poll and emit events, which signal some other code to be executed potentially in another thread. For example, anything that does a blocking operation can be run on a different thread pool, where it has bunch of spare threads and a lower priority in OS, which prevents it from interrupting the precious event loop from running and executing low latency code.
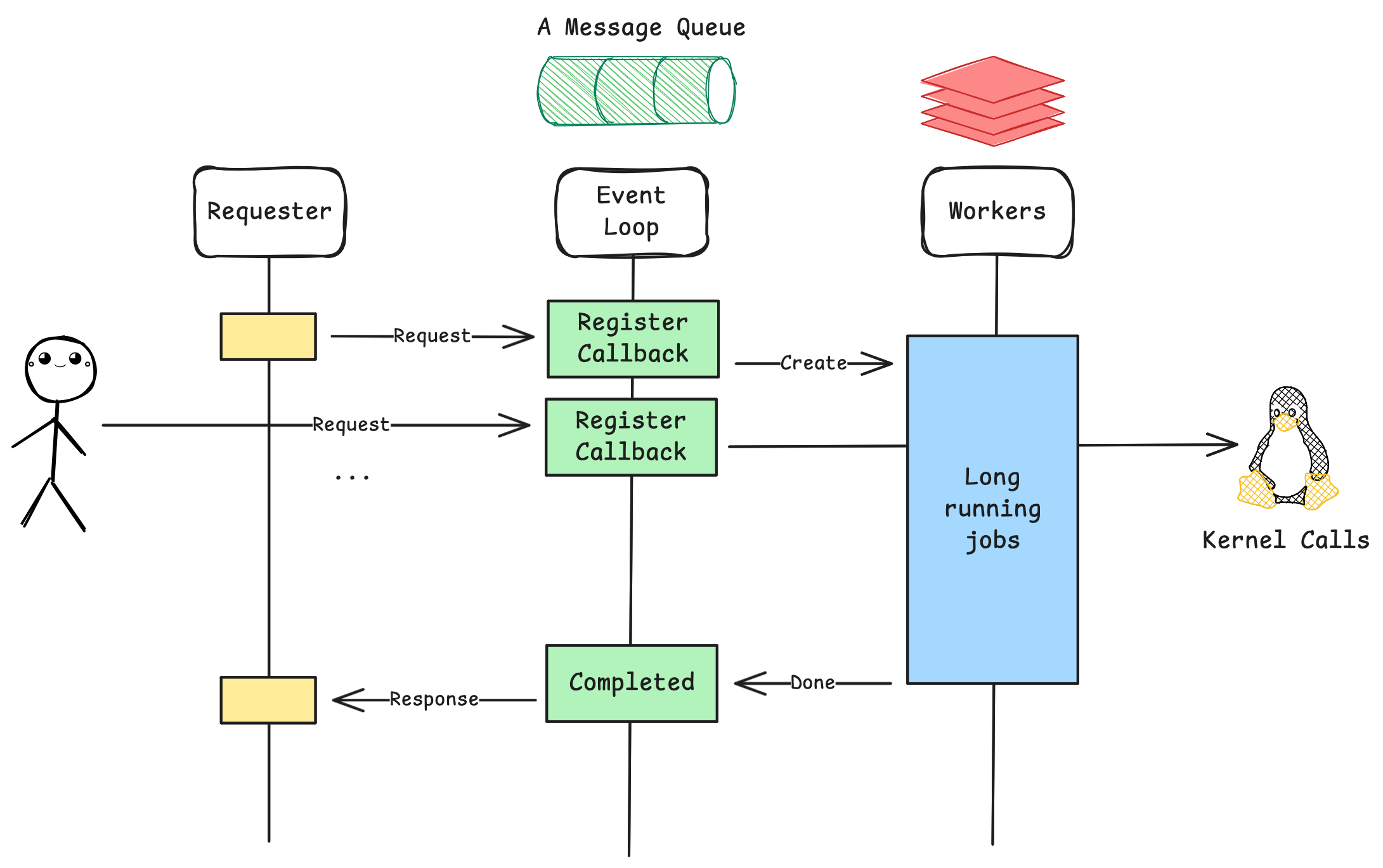
Let's think about how we can achieve sleeps and waits, calling Thread.sleep delegates scheduling to the operating system by blocking the thread until the given time has passed. Instead of blocking a thread, let's build an event-loop system. Instead of calling Thread.sleep, we can submit some job to a queue with a given delay, we will be creating a pub-sub model, where some jobs are scheduled via a publisher thread and the jobs are consumed and executed when the time comes on a consumer thread.
Schedule schedule = new Schedule();
Thread publisher = new Thread(() -> {
while (!Thread.currentThread().isInterrupted()) {
List<Message> messages = pollMessages();
messages.forEach((message) -> {
schedule.queue(message::sendNotification, 2000);
});
Thread.sleep(1);
}
});
Thread consumer = new Thread(() -> {
long lastRunAt = System.currentMillis();
while (!Thread.currentThread().isInterrupted()) {
List<Jobs> jobs = schedule.getJobBetween(lastRunAt, System.currentMillis());
jobs.forEach((job) -> job.run());
lastRunAt = System.currentMillis();
Thread.sleep(1); // 1 milliseconds precision
}
});This is better now, as we are only running 2 threads and not running any major blocking code that affects our performance. Of course it is possible to improve this by using OS level calls. It can utilize hardware to trigger some events based on a timer or hardware level interrupts. However I wanted to show you how we can achieve something similar without relying on OS internals. This logic is actually similar to how Asynchronous frameworks are built, such as Netty. A key distinction is the use of asynchronous triggers and low-level parking mechanisms instead of Thread.sleep, allowing for more efficient CPU utilization and better responsiveness. Also in this example, our Schedule object acts similarly to a message queue, which is more popular choice in event queues, where different messages are passed around to perform different actions.
Inside this event loop, we are currently calling some get job between method to constantly check if a new job has arrived. This is not very efficient. Instead, we could use something like epoll_wait with io_uring ,which is a kernel call that blocks the thread until some change happens on a given file descriptor. Alternatively, if you are waiting messages to arrive in your message queue, you can use pthread_cond_signal with pthread_cond_wait, which allows a thread to wait until a signal is given. In this case, our event loop can wait if all messages are processed and while adding a message to the queue, we can call signal to wake up the event loop. Those kernel calls do it efficiently, so that you are not wasting CPU cycles while doing this wait.
For now we have just considered a static blocking call, sleep(...). However, most of the blocking calls we typically use are I/O related. For example network I/O, where you send a request and wait for a response to come back. To write fully non-blocking code, you have to spin-up a thread for each step that has blocking logic (wait). You also need to write schedulers and coordinators to manage those jobs and make sure they are running with high concurrency and low latency. So, developers of Java said concurrency is really hard to manage manually, let's invent some construct that allows developers to write asynchronous code, and that's how Future is born.
Java's Future
With a Future, the developer doesn't have to worry about blocking calls as often, because a Future is basically a chain of callbacks. When you construct a future, you register callbacks in your event loop. Whenever the executed code inside the Future has finished, the event loop calls your registered callback. This paradigm decouples the task submission from thread management.
CompletableFuture<List<Message>> messagesF = pollMessages();
List<Message> messages = messagesF.join();A simple example to convert a future to a blocking call
A Future is a wrapper that can have values put inside from other sources in a future time. For example, when you call .join(), your current thread waits until the result inside the Future object is available. The result is usually set from another thread. So you can pass around those Future objects safely in your code without blocking your current thread.
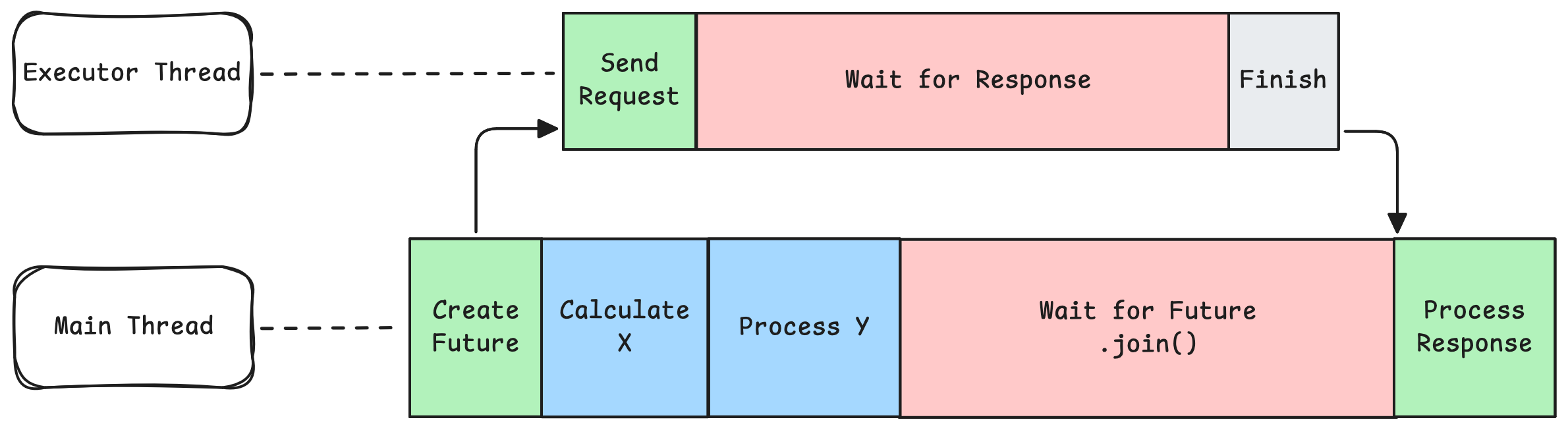
CompletableFuture<Object> future = new CompletableFuture<>();
// Spawn a thread to do calculation in the background
new Thread(() -> {
Object result = longRunningCalculation();
future.complete(result);
});
// Wait until the result is available (complete) is called.
future.join();Moreover, you can transform and chain Futures together to do more complex operations such as,
CompletableFuture.supplyAsync(() -> calculateString())
.thenApply((String::toUpperCase))
.thenApply(s -> s + " world")
.thenAccept(System.out::println);Moreover, futures can be chained together, so ones execution will depend on another's result.
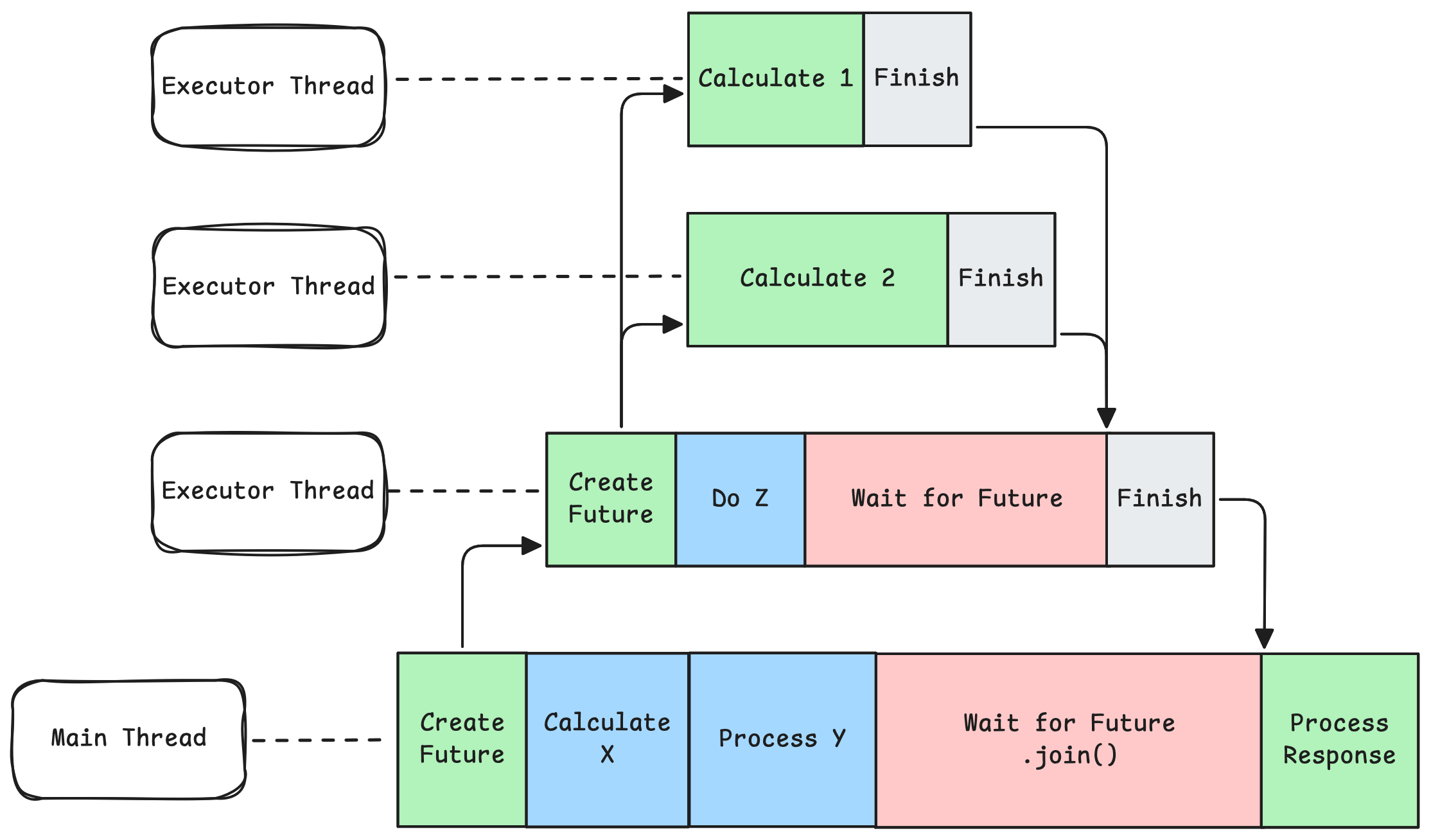
CompletableFuture<String> f1 = CompletableFuture.supplyAsync(() -> "hello");
f1.thenCompose(s -> CompletableFuture.supplyAsync(() -> s + " world"));As you can see, using a Future as a developer is something you need to get used to, you can't write code sequentially as before. You have to rewrite it using a special syntax. For example, a blocking code for polling and sending notifications can be written as,
List<Message> messages = pollMessages();
messages.forEach((message) -> {
Result result = sendNotification(message.notification);
persistResult(result)
});But as usually polling, sending and persisting are waiting operations, let's modify them to return Futures. Therefore we need to write our code in the following way to prevent blocking calls. First, we modify pollMessages, sendNotification and persistResult to return futures, so they are not blocking.
pollMessages()
.thenComposeAsync(messages -> {
List<CompletableFuture<Void>> futures = messages.stream()
.map(message ->
sendNotification(message.notification)
.thenComposeAsync(v -> persistResult(message), executor)
)
.toList();
return CompletableFuture.allOf(futures.toArray(new CompletableFuture[0]));
}, executor);As you can see, a simple sequential code had become something obscure pretty quickly. We are not doing any kind of trick to run stuff in parallel as well, we just want to run asynchronous operations without blocking.
Scala's Way of Sequentialism
By using futures, we have the flexibility of keep running more async code without waiting for each one of them. However, an application developer's code is usually written in a sequential way, so that each operation happens back to back. Therefore, futures are usually composed in a nested way. This nesting creates a readability and maintainability issue. So Scala came up with a clever way to manage those nestings, a for comprehension.
for {
messages <- pollMessages()
result <- sendNotifications(messages.notifications)
_ <- persistResult(result)
} yield (result)This approach tries to create a sequential syntax for writing asynchronous code unlike Java's traditional Future chaining. However it comes with several limitations,
- You still need to write code using a special syntax.
- Early returns are not possible
- Error handling is still nested.
- Iterative code doesn't translate directly.
Those limitations also apply to Java's Future, but demonstrating them would require a different syntax, I found scala's syntax to be slighltly more friendly, but I will show you why it is still limiting. For example you can't conditionally run a code without nesting.
for {
result <- sendNotifications(messages.notifications)
// This is not a valid syntax
if (result == Result.ERROR) {
_ <- reportErrors(result)
return false
}
_ <- reportSuccess(result)
} yield (true)You have to write it using nested for comprehensions, so each decision point in your comprehension tree needs to branch out.
for {
result <- sendNotifications(messages.notifications)
innerResult <- result match {
case Result.ERROR => for {
_ <- reportErrors(result)
} yield false
// For comprehension is not recommended for single futures.
case _ => reportSuccess(result).map(_ => true)
}
} yield innerResultFor error handling, similarly you have to write recover blocks, you can't use your daily tool of try { .. } catch { .. }.
for {
result <- sendNotifications(messages.notifications).recoverWith { case err =>
for {
_ <- reportError(err)
_ <- rollback(messages.notifications)
} yield false
}
} yield resultNesting also forces you to unify the type of result. Normally, you could assign the result of error to a different variable and called return early on to prevent code from incrementing sequntially. Moreover, all those limitations still apply to Java's traditional Futures as well.
Sequentialism as First Class Citizen
We now know why Java's Futures exist and how Scala's for comprehension syntax try to solve some fundamental issues with those. However, it is obvious to see Java wasn't designed as first-class asynchronous programming support, where Scala tried to patch some of its inherent issues. However, Scala, never tried to replace Java, but rather tried to extend it. For comprehensions has been a big deal, but it also brought a lot of other benefits as well. On the other hand Kotlin directly targeted Java as its contender and tries to replace it. One of the distinct features of kotlins is coroutines.
Instead of relying threads, which are expensive operating-system level constructs, Kotlin introduces coroutines, which are runtime-level lightweight constructs. Coroutines do still run on threads, but their execution is not strictly tied to a single thread, so they can switch threads during runtime. This flexibility makes them lightweight, similar to jobs submitted to the thread pools as we have shown in the first chapter. However, Kotlin has first-class support for coroutines using its language features, most importantly suspend.
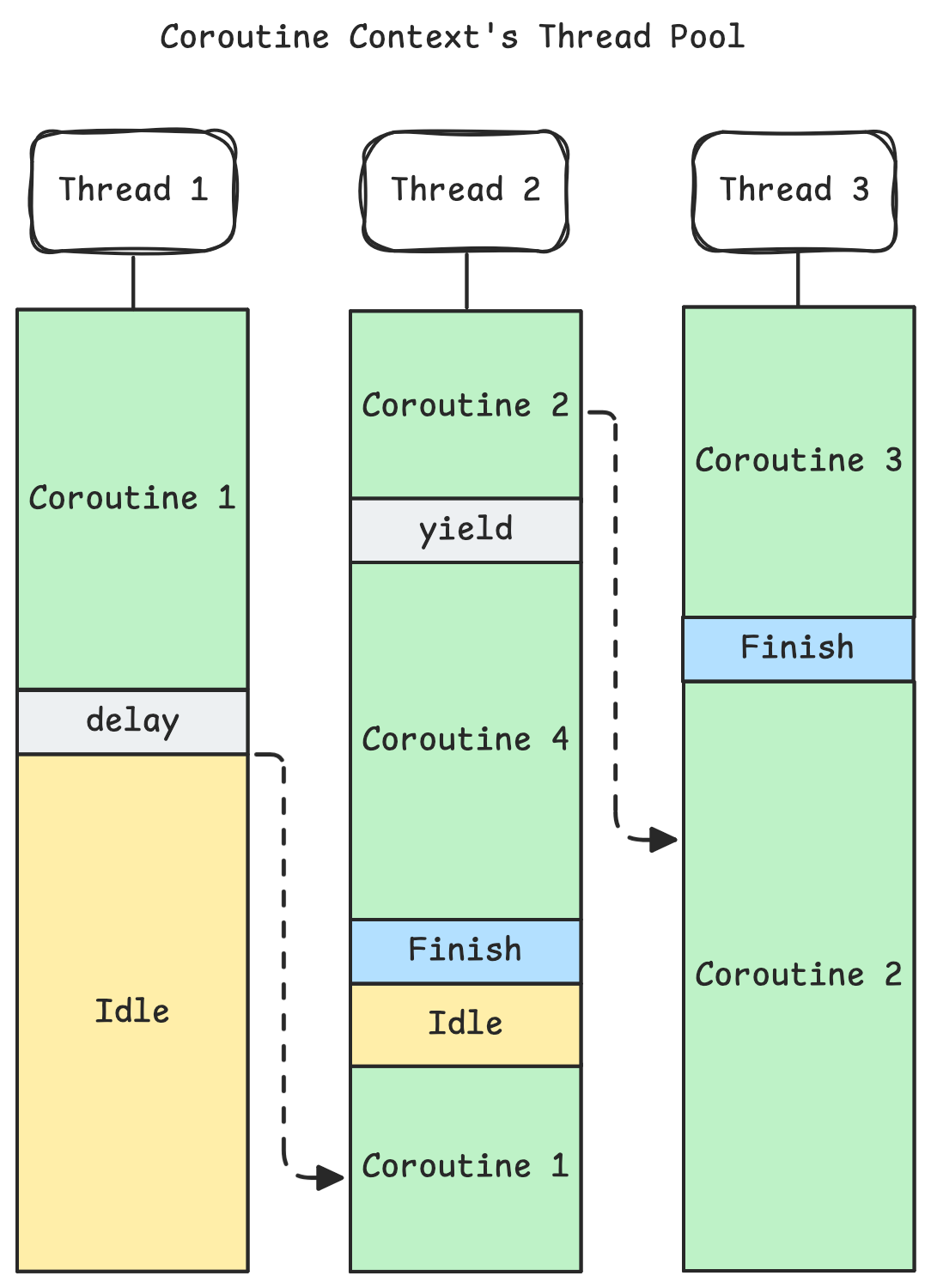
Unlike threads, coroutines are not paused randomly to let other coroutines run. Note that the thread that is running coroutines can be paused randomly by the OS, that is not possible to prevent, however the coroutine scheduler doesn't internally pause coroutines. On contrary, those coroutines show a cooperative approach. They yield the current execution whenever possible. Most importantly, they yield during asynchronous operations, where they wait for an operation result. Therefore underlying libraries should expose those asynchronous operations as suspend functions to allow benefiting from Kotlin's coroutine features.
Also the best thing about suspend functions is its written the traditional sequenatial way. Sequential asynchronism is the first class citizen, whereas controlled asynchronism is also provided using other interfaces, including Future or Kotlin's Deferred construct.
suspend fun processMessages() {
val messages = pollMessages();
messages.forEach { message ->
sendNotification(message.notification)
delay(2000)
}
}Wait, that must be blocking right? No, there is no blocking code here! The methods pollMessages, sendNotification and delay is actually suspend methods. For example, when you are polling messages, it actually does it asynchronously and the coroutine is yielded during this polling process, thus it doesn't block the running thread. Same goes for send and delay. The delay is a native implementation, where a scheduler stops the coroutine in the background and continues it when the given time has arrived. So we were able to benefit from an event-loop without writing the nested futures and executors. If you are curious about how event-loops are implemented, check the C++ Worker implementation for Kotlin.
Having Kotlin's suspension language feature solved almost all of our pain points as developers with writing asynchronous code. Most importantly, writing code that does asynchronous stuff without inducing any parallelism. A developer doesn't necessarily care how those futures are chained and handled, especially if they are writing data intensive applications. If a developer needs explicit parallelism, they can use Kotlin's provided Deferred variables.
val messagesD: Deferred<List<Message>> = async { pollMessages() }
val messages = messagesD.await() // calling await is "suspend"
sendNotifications(messages)Moreover, a user might dispatch the given suspend call in a different coroutine context, or thread pool. This is specifically important if an old-school blocking code needs to be executed inside a suspend function.
val messages = withContext(Dispatchers.IO) {
pollMessages()
}
sendNotifications(messages)Implicit Parallelism: Know Where to Go
A step forward from sequenatial asynchronism can be thought as implicit parallelism, where the execution of code happens sequentially and asynchronously at the same time. How? It is only possible by the programming language's support. Let's assume when you call,
val messages = pollMessages()
val users = fetchUsers()the code fetchUsers() is executed before pollMessages() is finished, because they are mutually exclusive events. This can be traditionally done using a futures approach.
val messagesF = pollMessages()
val usersF = fetchUsers()
val (messages, users) = awaitAll(messagesF, usersF)However having this in programming language's native construct can both help users write performant code, whereas it can also cause them to write buggy code easily, as the default assumption is sequentialism. Therefore, I think a paradigm where implicit parallelism is possible, but it should be assessed very carefully while using, as there is no way to prevent unintentional race conditions without doing any formal verification. Even in runtime, you might see flakiness issues, as you are starting to build a distributed by default environment. We already know distributed systems is already hard to ensure correctness without doing formal verification, we are pushing this complexity towards our code.
That's why I think Kotlin deserves some praises on how it handles paralellism, where it is explicit and easy to shift between paradigms.
val messages = async { pollMessages() }
val users = async { pollMessages() }
sendNotifications(messages.await(), users.await())I hope to see some language features where calling a second await is unnecessary because it is already awaited in the past, similar to smart casting, where a nullable type can be cast to be a not-null type automatically if some check has been performed.
Final Remarks
There is still a lot to talk. There are bunch of other languages and frameworks that handle asynchronous execution in various ways, such as Go's goroutines, javascript's async/await, python's asyncio, Rust's tokio etc. There is still more in Java related to Future, Mono, Flux – Scala's execution contexts, Cats, Akka – Kotlin's coroutine contexts, dispatchers, Flows, Channels and many more if you are interested in reading about them.
We see how programming languages have evolved to catch up with the developers need. Our hardware has improved, our CPUs have many spare cycles, now we are usually a larger share of our time for waiting tasks, such as disk or network. Initially we have written code sequentially, later we have built Futures, executors and event loops. Finally, we have seen how syntax evolved to support asynchronous programming in an easier and more readable way. I do believe asynchronous programming is still open to improvements, frameworks and languages used will keep improving, sequential asynchronism will increase its popularity.