Start with a clean slate: Integration testing with PostgreSQL
We have been using PostgreSQL as our primary database in production for 4 over years, however over time, as our database grew bigger and reached over 500 tables in a single monolithic application, we had to come up with smart ways to manage it. PostgreSQL is a database that is capable of handling hundreds of tables and billions of rows, however it doesn't necessarily mean it will be easy to develop applications in a such setting. In this post, I am going to write down how I have tackled some bottlenecks in the integration testing pipeline at Carbon Health by speeding up and increasing isolation of our integration test pipelines. The solution powers our CI/CD pipelines for the last 2 years.
This blog post's topic is my upcoming presentation at PGDay Chicago 2025. Conference slides accessible at https://pgday.dogac.dev/.
Link to the tool: github.com/Dogacel/pg_test_table_track
Problem
A short anectode on monoliths: Microservices is something we often hear about but usually a far reality for many of us. Monoliths (monos: single/one, lithos: stone) still work pretty great in many real-world settings and they only bear a subset of management problems microservices have. One of the core problems in Monoliths is its huge codebase and slow build times. You don't need to open 3 pull requests just to do some CRUD operations on a basic database table, and jump back a couple PRs later, because you forgot to add a field to your proto definitions and you gotta open 3 more PRs to add that. That sounds neat, however most likely, the total CI/CD runtimes of your 6 PRs will be still less than a single PR check in the monolith's PR, just to see your linter failed after 45 minutes, because you failed to define a constant for a magic number, yikes. If you want to have a productive and effective development environment with your Monolith, you have to do some optimizations in your CI/CD and testing environment.
Background: So a little background about our company before we start,
- Our tech-stack consists of a monolithic server supported by 30+ micro-services.
- We host our services on cloud, our primary choice of database is PostgreSQL.
- We have over 500 tables serving more than 10TBs of data.
- We have about 6 distinct development teams.
As you might have guessed, those 500 tables are causing a big trouble in our CI/CD pipelines. Almost more than half of our 9000+ tests in our monolith are also integration tests, meaning they use a PostgreSQL instance to run queries. And over time, our pipeline has became painfully slow and annoying to work with, which lead me to come up with a solution.
Integration tests
Integration testing checks whether different parts of a system work together correctly as a whole. Unit testing focuses on testing individual components.
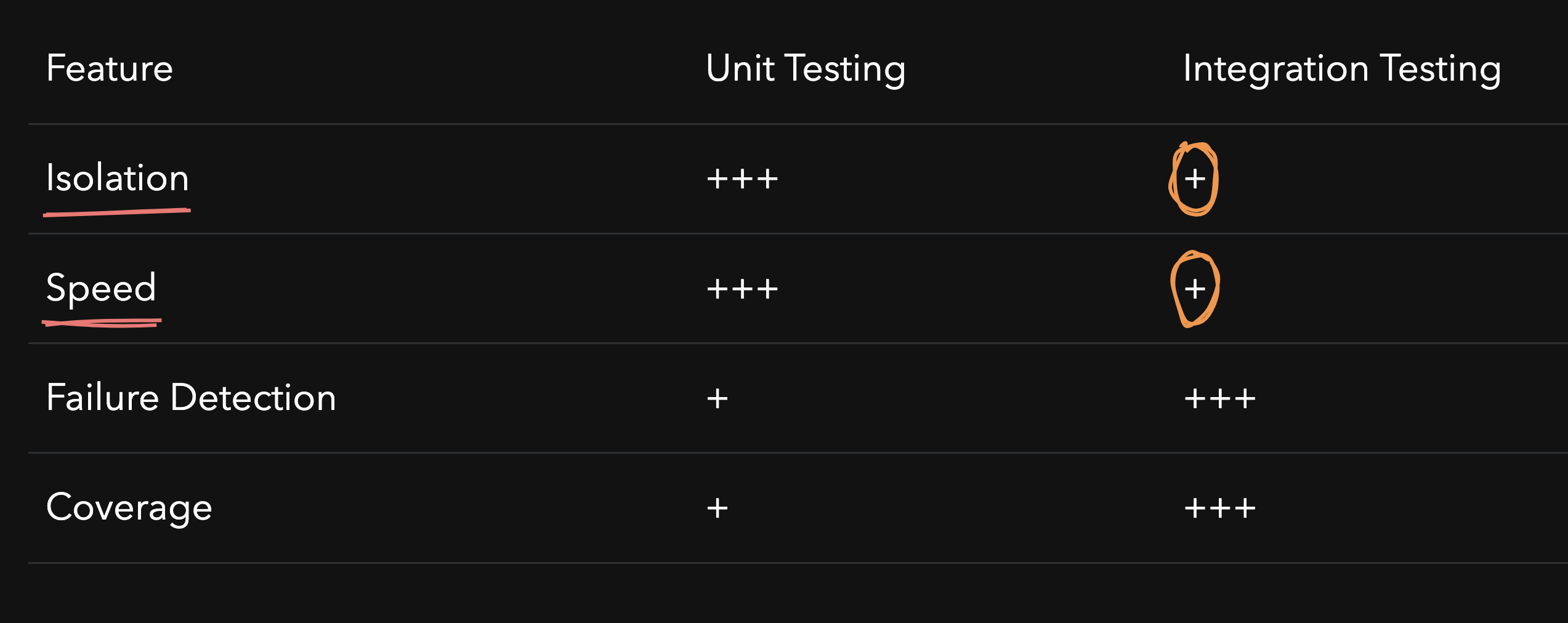
Even though unit tests are much superior in terms of isolation and speed, they are not as good for covering the end to end flows and detect real-life failures. That's why we have extensively written integration tests to ensure our Monolith is tested well before release. Based on our experience, setting up scenarios and running the actual DB queries in tests really help catching bugs early on.
So, what's the catch? Writing integration tests are painfully hard, as your data dependencies, such as foreign key constraints, make initializations a hassle for developers. Moreover, your database keeps a state, therefore you need to ensure it doesn't leak in-between tests. So let's explore our options in order to achieve a fast and isolated environment.
Wrapping every test with transactions
At first, it sounds like a good idea. In reality, it is a terrible idea. PostgreSQL supports some sort of nested transactions, also called SAVEPOINTS. However a failure inside a transaction aborts the rest. Therefore, it is not possible to truly wrap every test inside a transaction and run, as some errors might result parent transaction to abort. Moreover, wrapping with additional transactions would result in altering the runtime behavior of tests. This is not something we want, as it might result in hard to debug errors that are only faced during tests, as well as behavioral differences from the actual production environment, which might cause some bugs to be not caught early on.
Fresh DB for each start
If you want to maximize isolation, go ahead and create a fresh DB instance for each of your tests. This worked fine in our microservices where the number of tables and tests were lower. However in monoliths, you will quickly realize this is a slow process. We have thousands of migration files, but we can always use a schema dump. In our case, we used rake:schema:dump. I highly encourage readers to experiment with TEMPLATE databases as well. However, initialization takes around 400 milliseconds, this results in a little over 1 hours of just DB initialization time for our 9000+ integration tests.

Cleaning all tables
This was the initial approach in our codebase, maintaining a hand-curated list of DELETE TABLE queries. However it has some drawbacks,
- Order of deletions matter as there are foreign keys.
- Sometimes tables were missed from the, resulting in flakiness.
- Sequences and Materialized Views require special attention.
For number 3, our codebase doesn't truly benefit from both, so we didn't care. However, this approach was still too slow and maintaining the list was super annoying. Adding a new table into this list was very hard, you would see weird foreign key errors, random test failures and so. Also, there is no guarantee that your hand-crafted list contains all the necessary tables in the right order. Therefore, a developer might randomly encounter a flakiness while writing a test without knowing it is related to some artifacts leftover from the recent tests.
Actually I have had this issue once, and it was super annoying to fix. Updating our build tools resulted in changing the execution order of tests, which ultimately lead to flakiness. It took me an enourmous amount of time to figure out that test order was changed and the bug was caused by a state leak between tests.
We also experimented withTRUNCATEoverDELETE. However it slowed down our pipelines even more. I think it is because our test tables had a small amounts of data, which made truncate less effective and caused overhead.
Final Solution
So I have decided, our final goal should be
- Make each table fresh before each test
- Clean the state as fast as possible
- Get rid of hand-crafted lists as entropy always wins
So I built a solution that uses PL/pgSQL to automatically clean all tables that are used in-between tests.
Storing Access
If there are bunch of tables, trying to clean up all of them would generate a big overhead. So instead of that, what about only cleaning the ones that contains data? To do that, we need to store the tables that are used during testing somewhere.
CREATE TABLE IF NOT EXISTS test_access(table_name varchar(256) not null primary key);Later, create a function / trigger that adds a given table name to the list.
CREATE OR REPLACE FUNCTION add_table_to_accessed_list() RETURNS TRIGGER AS $$
BEGIN
--- Assuming that the table name is passed as the first argument to the function.
INSERT INTO test_access VALUES (TG_ARGV[0]) ON CONFLICT DO NOTHING;
RETURN NEW;
END $$ LANGUAGE PLPGSQL;
Spying on tables
In order to spy on tables that are modified, we can use triggers. This trigger will be executed before every insert, which ensures we capture all tables that are altered during the test run.
CREATE OR REPLACE FUNCTION setup_access_triggers(schemas text[]) RETURNS int AS $$
DECLARE tables CURSOR FOR
SELECT table_name, table_schema FROM information_schema.tables
WHERE table_schema = ANY(schemas)
AND table_type = 'BASE TABLE' --- Exclude views.
AND table_name NOT IN ('test_access', 'schema_migrations');
--- Prevent recursion when an insertion happens to 'test_access' table.
BEGIN
--- Create a table to store the list of tables that have been accessed.
EXECUTE 'CREATE TABLE IF NOT EXISTS test_access(table_name varchar(256) not null primary key);';
FOR stmt IN tables LOOP
--- If the trigger exists, first drop it so we can re-create.
EXECUTE 'DROP TRIGGER IF EXISTS "' || stmt.table_name || '_access_trigger" ON "' ||
stmt.table_schema || '"."'|| stmt.table_name || '"';
--- Create the on insert trigger.
--- This calls `add_table_to_accessed_list` everytime a row is inserted into the table with table name.
--- The table name also includes the table schema.
EXECUTE 'CREATE TRIGGER "' || stmt.table_name || '_access_trigger"' ||
' BEFORE INSERT ON "' || stmt.table_schema ||'"."'|| stmt.table_name || '"' ||
' FOR EACH STATEMENT ' ||
' EXECUTE PROCEDURE public.add_table_to_accessed_list (''"'||
stmt.table_schema ||'"."'|| stmt.table_name ||'"'')';
END LOOP;
RETURN 0;
END $$ LANGUAGE plpgsql;Cleaning the tables
As a last step, we need to create a function that allows us to clean all tables that are accessed during the last test execution cycle. We disable foreign keys before deleting to ensure deletion order doesn't matter as our final goal is to clean all tables.
CREATE OR REPLACE FUNCTION delete_from_accessed_tables() RETURNS int AS $$
DECLARE tables CURSOR FOR
SELECT table_name FROM test_access;
BEGIN
--- Disable foreign key constraints temporarily. Without this, we need to clear tables in a specific order.
--- But it is very hard to find this order and this trick makes the process even faster.
--- Because we clear every table, we don't care about any foreign key constraints.
EXECUTE 'SET session_replication_role = ''replica'';';
--- Clear all tables that have been accessed.
FOR stmt IN tables LOOP
BEGIN
EXECUTE 'DELETE FROM '|| stmt.table_name;
--- If we accessed a table that is dropped, an exception will occur. This ignored the exception.
EXCEPTION WHEN OTHERS THEN
END;
END LOOP;
--- Clear the list o accessed tables because those tables are now empty.
EXECUTE 'DELETE FROM test_access';
--- Turn foreign key constraints back on.
EXECUTE 'SET session_replication_role = ''origin'';';
RETURN 0;
END $$ LANGUAGE plpgsql;Embedding into Tests
We have developed an interface / trait called CleanDBBetweenTests and every integration test in our system extends this trait. Inside this trait, we have setup some before and after test triggers to ensure our tables are cleaned.
def clearAccessedTables(): Unit = {
finishOperation(sql"""SELECT public.delete_from_accessed_tables()""".as[Int])
}
def setupTestTriggers(): Unit = {
finishOperation(sql"""SELECT public.setup_access_triggers(array['test_schema'])""".as[Int])
}
trait CleanDBBetweenTests extends BeforeAndAfterEach with BeforeAndAfterAll { this: Suite =>
override def beforeAll(): Unit = {
setupTestTriggers()
clearAccessedTables()
}
override def beforeEach(): Unit = {
clearAccessedTables()
}
override def afterAll(): Unit = {
clearAccessedTables()
}
}Results
Using this approach, we were able to cut our CI/CD times by 30%. The speed increase and better isoaltion greately improved our developer experience. We have never had issues with our table cleaning approach since we first rolled out this tool. As our codebase keeps growing, without this change, our current CI runtime would be more than 1.5 hours by now. Speeding up our CI times didn’t only decrease our bills but it also motivated people towards writing more code and tests as the PR feedback cycle was much quicker
Future Work: Exploring strategies to support constant rows that would stay during all execution cycles, as well as setting up scenarios. Moreover, UNLOGGED TABLEs can potentially speed up the execution further more.
Last words... I have decided that I should open-source this tool so everyone can benefit from it. Your feedback is very valuable, please let me know what you think.